

A GPU Pod can be launched in seconds.
A fully functional, GPU-enabled environment can be set up in less than a minute. Supports various GPU models, including B300, B200, and H200.

Deploy quickly with just a few clicks.
Run workloads across all our regions for low-latency performance and global reliability.

Enable automatic scaling with our platform.
Go from 0 to 100 compute nodes, adapting to your workload in real time, and pay only for the resources you actually use.

From conception to deployment, all in one step.
Simplify every step of your workflow, allowing you to build, scale, and optimize without managing infrastructure.
Create
Train models, render simulations, or process data—without any restrictions or lockouts.

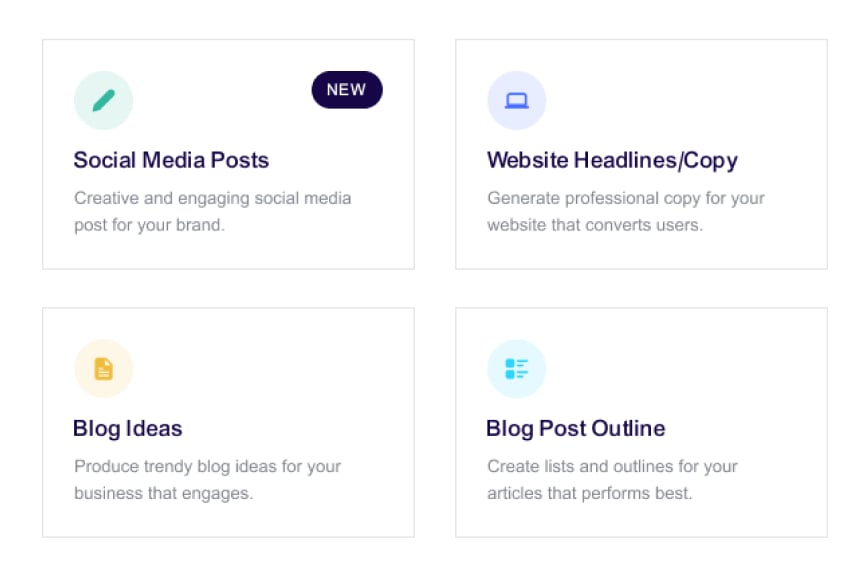

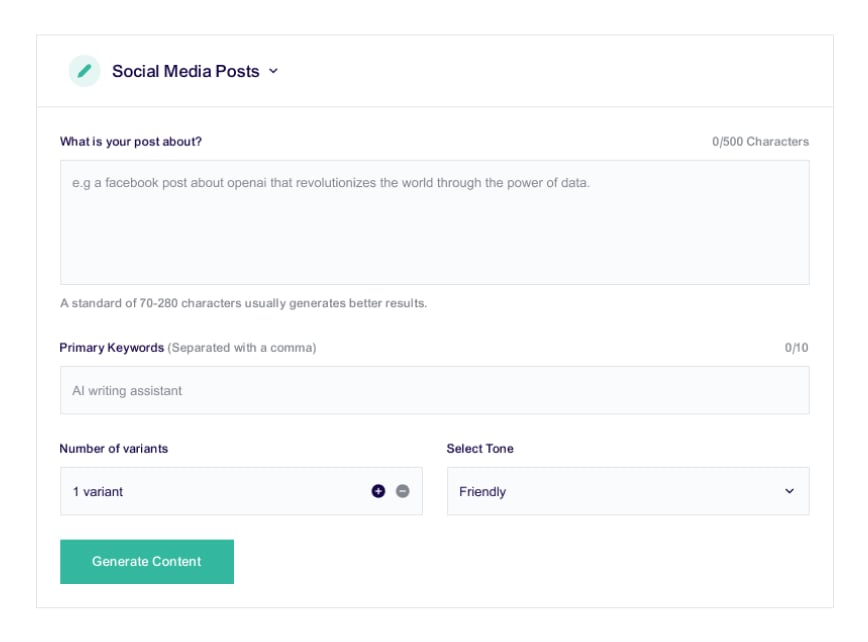
Iteration
Experiment with confidence, leveraging instant feedback and safe rollback capabilities.
Deploy
Auto-scale across regions-zero idlecosts, zero downtime.

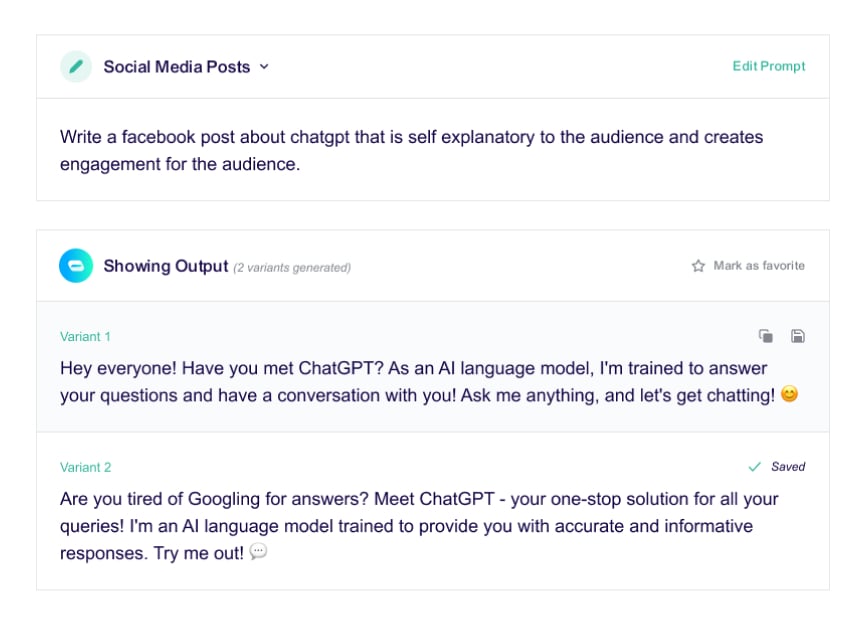
Scale with our platform when you're ready for production.
Powerful compute, effortless deployment.

Smooth operation.
It can handle failover, ensuring your workloads run smoothly—even with limited resources.

Managed orchestration.
It seamlessly queues and distributes tasks, saving you the hassle of building your own orchestration system.
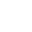
Real-time logs.
Get real-time logs, monitoring, and metrics—no custom frameworks required.

Autoscale in seconds
Instantly respond to demand with GPU workers that scale from 0 to 1000s in seconds.

Zero cold-starts with active workers.
Always-on GPUs for uninterrupted execution.

Fast cold start.
Lightning-fast scaling, with a cold start time of less than 200 milliseconds.